

Данные: собираем — сортируем — изучаем
Первый блок, которому уделяется внимание — сбор, анализ и визуализация данных, то есть техническая интеграция и хранилище данных DWH.
Техническая интеграция пронизывает любой IT-продукт, и эта тема достойна отдельного освещения. Упомяну лишь, что у нас используется шина данных на базе Apache Kafka, обернутая в собственные API для нативного вызова из Java и .Net кода, либо через универсальный REST-интерфейс. Интеграционная модель данных, базирующаяся на КМД (корпоративной модели данных), является платформо-независимой и унифицирована среди всех внутренних систем. Согласитесь, бизнес компании не меняется в зависимости от используемых IT-систем, поэтому и модель данных определяется исключительно бизнес-процессом.

Типовой IT-ландшафт
Хранилище данных или Data Warehouse. Разработку этого продукта мы начали в конце 2018 года. Основной целью было создание единого полностью интегрированного и архитектурно корректного, расширяемого хранилища информации из внутренних и внешних источников, в первую очередь для решения задач анализа данных. Выбор пал на PostgreSQL, которая позволяет строить комбинированные хранилища в реляционных и нереляционных (Data Lake) моделях. Внутренняя архитектура трёхзвенная — Staging, Business Layer, Data Marts. В качестве ETL-средства используется Clover DX.
Открою вам секрет — мы не занимаемся разработкой структур данных самого хранилища за исключением дата-мартов. Структуры для хранения данных генерируются автоматизировано из КМД, а интерпретацию данных, приходящих из внешних источников, DWH выполняет с помощью внедряемого в настоящий момент MDM-решения Tibco EBX для управления мастер-данными в компании.
Визуализация данных или Портал корпоративной отчётности. Помимо анализа данных для автоматизированного принятия решений, первичная аналитика также представляет большую пользу для компании. Мы используем платформу Microsoft Power BI для визуализации отчетности, а для имитации единого окна для доступа к корпоративной отчетности разработан портал, обеспечивающий удобную навигацию среди отчетов Power BI.
Кидаем камни в воду и смотрим на круги
Инновации и эксперименты. Выход за рамки для тестирования гипотез необходим в процессе моделирования рынка. Так, в 2016-м году компания взяла курс на новые продукты, призванные существенно снизить риски для здоровья совершеннолетних потребителей табачной продукции.
У нас реализован стандартизованный подход к проведению экспериментов и апробации инноваций. Этот фреймворк объединил сразу несколько бизнес-концепций, методологий управления проектами и создания новых продуктов: design thinking, lean startup, AGILE, lean manufacturing. Главный принцип — принятие решений, в основе которых лежат данные, а не мнения. Эксперименты позволяют быстро протестировать идеи с минимальным бюджетом и риском для бизнеса. Как говорится, fake it to make it.
Роль IT в процессе проведения экспериментов двояка: с одной стороны, мы обеспечиваем необходимую минимальную автоматизацию для проверки бизнес-гипотез; с другой — также проводим собственные IT-эксперименты, связанные с тестированием не использованных ранее технологий, фреймворков и инструментов. В случае успеха включается отдельный процесс адаптации и превращения эксперимента в продукт. Процесс этот включает и защиту на уровне проектного офиса, и прохождение IT Architecture Board, и определение основных вех, по достижении которых эксперимент проходит стадии MVP (minimum viable product) и пилота, масштабируется и становится ближе к business as usual, переставая быть инновацией как таковой.
Играем, выбираем: моделирование рынка
Оценки исторической и текущей эффективности недостаточно — необходимо сохранить (или повысить) её в будущем, для этого важно понять, что произойдет с рынком завтра. Инновации приносят изменения в отрасль, и важно понимать и прогнозировать, что будет с рынком, самой компанией и крупными игроками-конкурентами в краткосрочной и долгосрочной перспективе. Важно оценить будущее в различных сценариях: при условной статичности (без инновации) и в условиях изменений — вывода на рынок новых продуктов, каналов, инвестиций.
Математическая модель рынка строится при помощи собранных данных и определенного инструментария, например, Anaplan — платформы для операционного и финансового планирования и моделирования бизнес-процессов.
В основе Anaplan лежит технология HyperBlock, позволяющая объединять характеристики вертикальных, реляционных и OLAP баз данных. HyperBlock фиксирует любые изменения на разных уровнях и оперативно меняет в соответствии с этими изменениями данные в связанных ячейках. Anaplan позволяет легко изменять параметры расчетов и бизнес-логики, адаптируя модели к реальному миру. По сути, это ПО, работающее на основе облачных вычислений, благодаря которому компании могут самостоятельно строить и развивать модели без привлечения консультантов и разработки собственной IT-инфраструктуры.
Для работы с большими данными мы используем математическую статистику, логику и визуализацию данных. Благодаря этому, датасаентисты строят модели, позволяющие оценить влияние инвестиционных инструментов и отследить закономерности. Результат работы такого специалиста — код с анализом данных в основе.
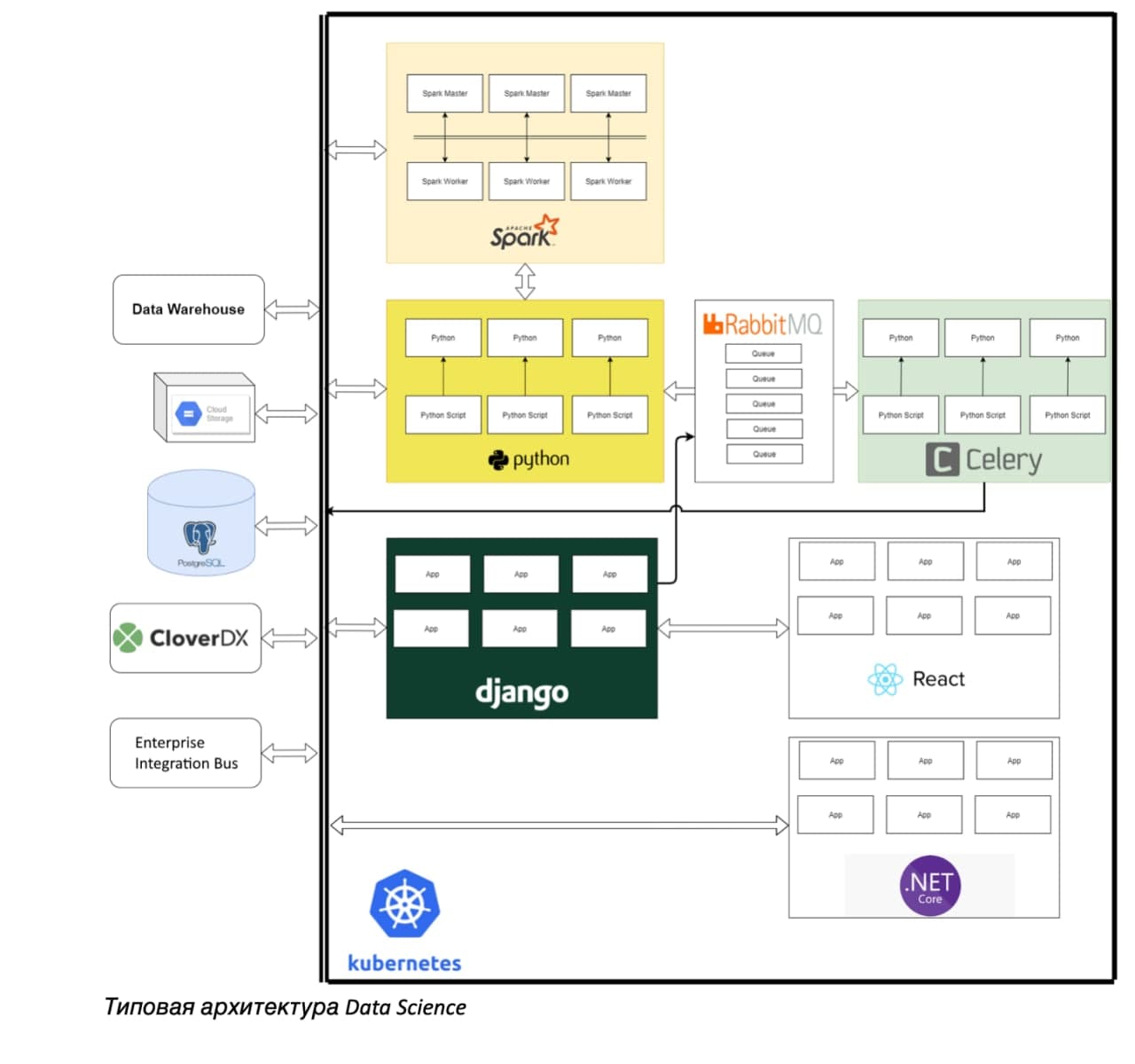
Типовая архитектура Data Science
В России мы используем как собственные данные из межсистемных интеграций, так и информацию от контрагентов, а также геоданные, которые показывают нам так называемые запрещающие факторы. Например, образовательные учреждения, рядом с которыми мы не можем вести свою деятельность.
Особенно важна «игра» с данными. Благодаря нашему хранилищу эти данные собраны и доступны в единообразном виде. Суть игры в тестировании разных моделей корреляции данных без ущерба всем остальным IT-процессам. Датасаентисты могут работать с одним из контейнеров, организованных на базе PosgreSQL. Контейнеры собраны под разные задачи и представляют собой изолированную площадку, «песочницу», где датасаентисты могут «проворачивать данные» и экспериментировать.
Для каждой задачи выделяется отдельное хранилище с доступом к данным из хранилища DWH. Время жизни дата-контейнера ограничено несколькими месяцами с возможностью продления. В случае неудачи контейнер уничтожается сразу, а в случае успеха — проходит путь стандартизации. Новые источники данных формализуются в виде модели данных, строится техническая интеграция, данные «приземляются» в корпоративное хранилище, при необходимости к данным можно подключить интерфейс, чтобы пользователь мог с ними взаимодействовать. Далее контейнер уничтожается.
Модель может быть математически построенной, но иногда, чтобы ее проверить, надо подключить пользователей, дать им возможность проводить what-if анализ, смотреть на визуализированный результат работы модели. Таким образом, из Data Science вырастает специфичная часть IT-ландшафта из набора технологий: кластеризации, python-based фреймворков и так далее.
Только после перечисленных этапов работы с данными начинается сам этап планирования, включающий в себя постановку целей и KPI, инвестиционный бюджет, инвестиционные инструменты, предложения от Data Science, каскадирование top-down, bottom-up корректировки, исполнение и корректировку планов. Об этапе планирования я расскажу в одном из следующих материалов.



